1. Généralités
Lorsqu’un paquet doit traverser un réseau, il n’a aucune idée du chemin qu’il va suivre.
La fonction principale de la couche réseau est d’acheminer les paquets
d’une source vers une destination.
Le routeur est le matériel qui réalise ce travail.
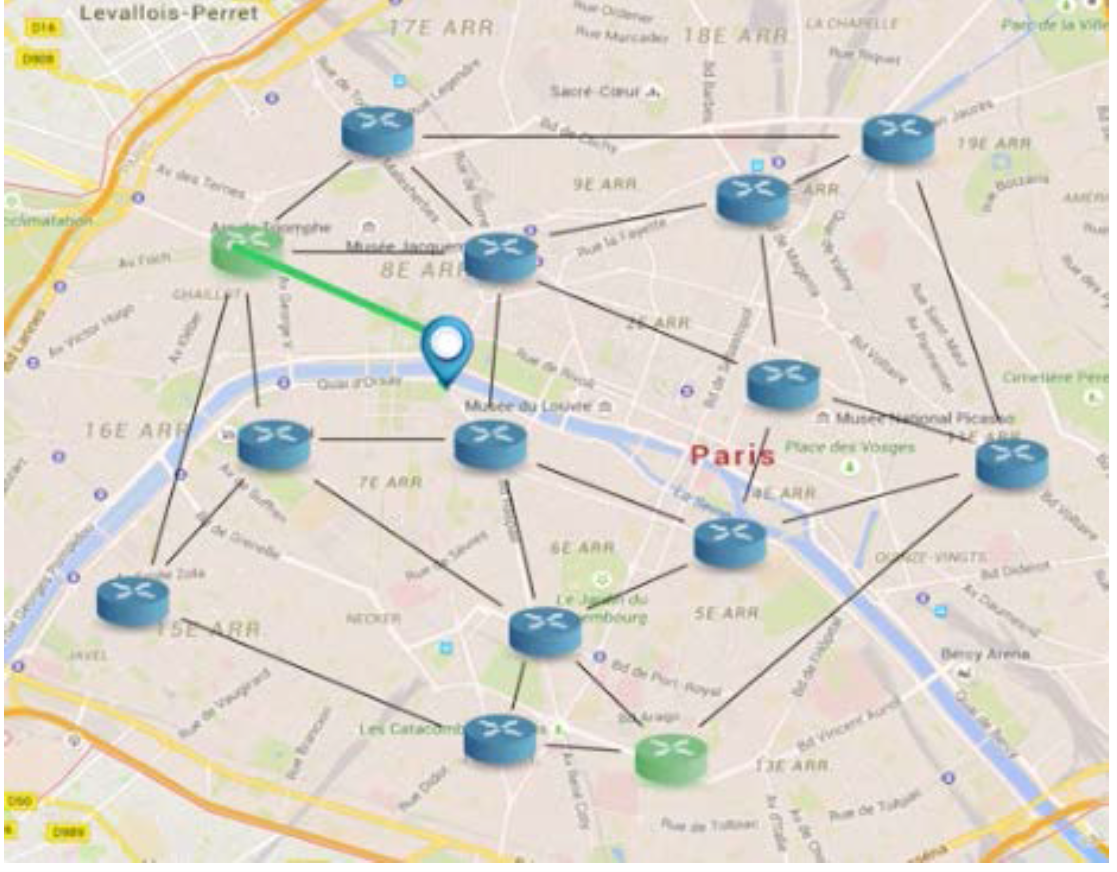
À chaque étape, un routeur relaye (oriente) le paquet en se basant uniquement sur l’adresse de destination de ce paquet.
Au sein d’un réseau, le relayage consiste à :
- trouver la bonne sortie (la bonne interface) sur le routeur ;
- trouver dans le réseau le chemin qui mène le paquet jusque-là.
2. Table de routage
Pour choisir les bons chemins, les routeurs s’appuient sur une table de routage. C’est une grande liste qui contient :
- les destinations possibles (réseaux ou hôtes) ;
- la passerelle (gateway) ou l’interface à utiliser ;
- un coût associé au chemin (métrique).
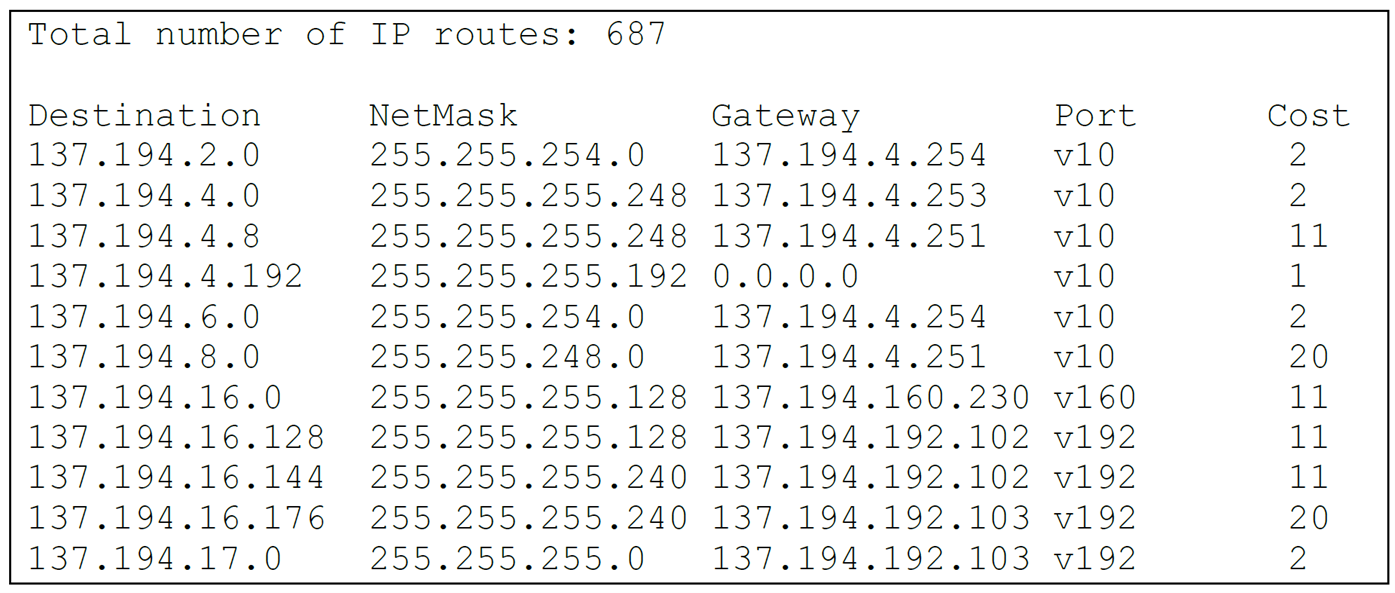
Une entrée typique de table de routage contient par exemple :
| Destination | Netmask | Gateway | Interface | Coût |
|---|---|---|---|---|
| 137.194.2.0 | 255.255.254.0 | 137.194.4.254 | v10 | 2 |
Ici, pour atteindre le réseau 137.194.2.0, le routeur envoie les paquets
sur son interface v10, vers la passerelle 137.194.4.254.
Cette table doit évoluer en fonction des pannes, des nouveaux liens, des changements importants du réseau… C’est précisément le rôle des protocoles de routage de maintenir cette table à jour.
3. Rôle d’un protocole de routage
Un protocole de routage définit la manière dont les routeurs échangent des informations pour mettre à jour leurs tables de routage. On distingue notamment :
- le routage statique (centralisé ou configuré à la main) ;
- le routage dynamique (basé sur un algorithme distribué).
3.1. Routage centralisé ou statique
Dans un routage centralisé, un centre de contrôle possède une vision globale du réseau, calcule les meilleurs chemins, puis renvoie les tables à tous les routeurs.
Dans un routage statique, les routes sont configurées à la main dans chaque routeur (sans protocole de routage). Cela peut convenir pour des réseaux simples, mais devient vite ingérable pour de grandes topologies et ne tient pas compte de la charge du réseau.
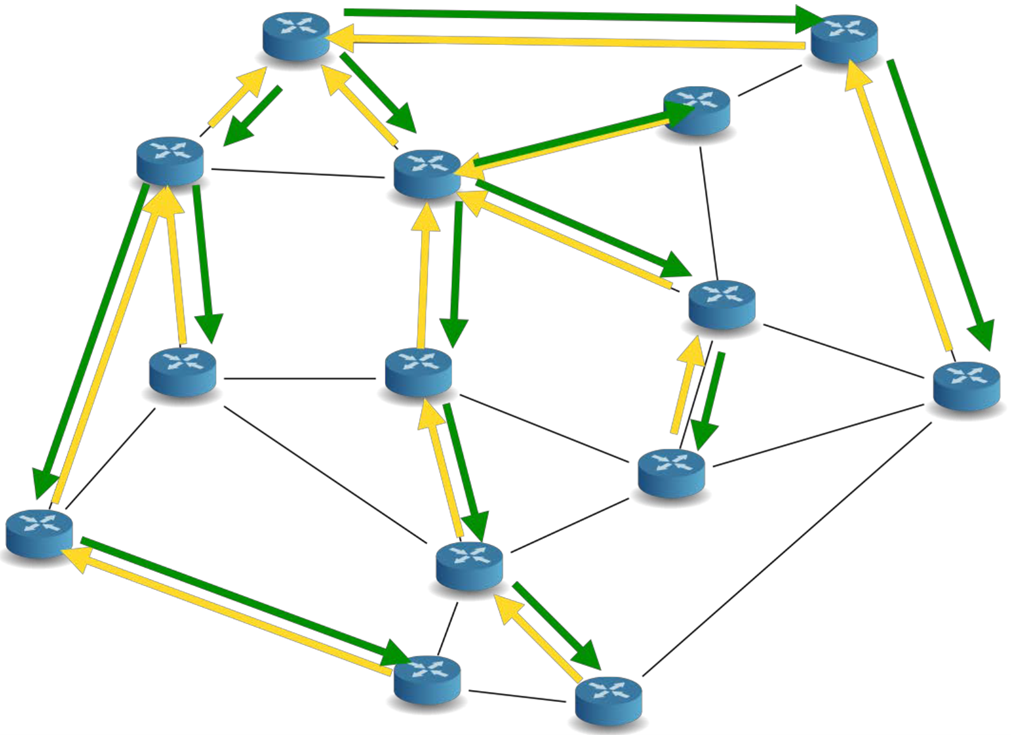
3.2. Routage dynamique
Avec un routage dynamique, chaque routeur exécute un algorithme distribué qui lui permet de mettre à jour automatiquement sa table.
Propriétés attendues d’un bon algorithme de routage :
- Fiabilité : les routes doivent être valides et cohérentes ;
- Stabilité : l’algorithme ne doit pas osciller en permanence ;
- Efficacité : les chemins doivent être « bons » (courts, rapides, sûrs, etc.) ;
- Coût raisonnable : les messages d’échange ne doivent pas saturer le réseau.
Il existe principalement deux grandes familles d’algorithmes de routage dynamique :
- les algorithmes à vecteur de distance (ex. RIP) ;
- les algorithmes à état de liens (ex. OSPF).
4. Routage par vecteur de distance : RIP
Les algorithmes à vecteur de distance sont basés sur l’algorithme de Bellman–Ford, utilisé dès les débuts d’ARPANET. Le protocole de routage RIP (Routing Information Protocol) en est une mise en œuvre classique.
4.1. Principe
Chaque routeur cherche à remplir sa table de routage en évaluant, pour chaque destination, le coût pour l’atteindre.
Le critère de coût est appelé la métrique. Suivant les protocoles, la métrique peut être :
- le nombre de sauts (nombre de routeurs traversés) ;
- le temps de transit ;
- le débit ou la charge des liens ;
- etc.
Dans RIP, la métrique classique est simplement le nombre de sauts. Deux routeurs sont dits voisins s’ils possèdent une interface dans le même sous-réseau.
4.2. Fonctionnement de l’algorithme
- Chaque routeur connaît la distance vers chacun de ses voisins (1 saut).
- Régulièrement, chaque routeur envoie à ses voisins le contenu de sa table de routage (son « vecteur de distance »).
- Lorsqu’un routeur reçoit un vecteur de distance d’un voisin, il met à jour sa propre table s’il découvre un chemin plus court vers une destination.
- Ce processus est itératif et se poursuit jusqu’à la convergence.
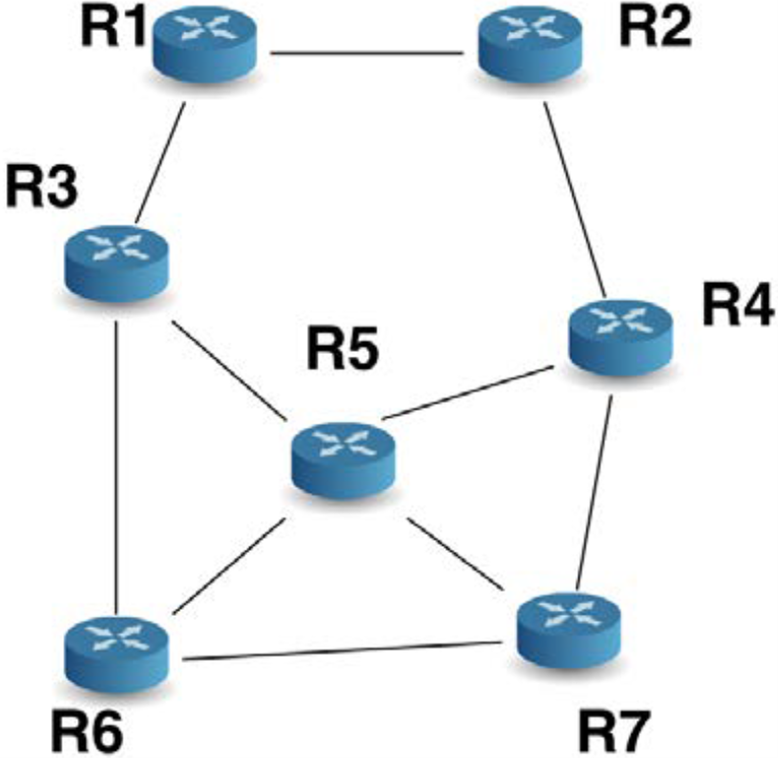
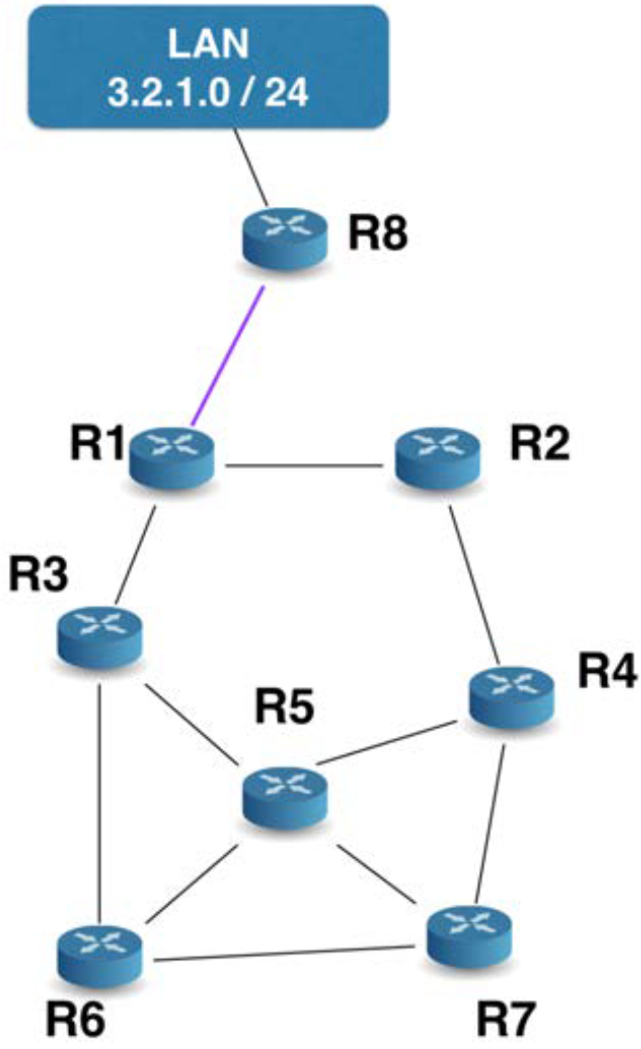
Après convergence (c’est-à-dire après que tous les routeurs ont échangé leurs informations et mis à jour leurs tables de routage),
chaque routeur connaît le nombre de sauts pour rejoindre le nouveau réseau.
Par exemple :
| Routeur | Distance (sauts) | Passerelle (gateway) |
|---|---|---|
| R1 | 1 | R8 |
| R2 | 2 | R1 |
| R3 | 2 | R1 |
| R4 | 3 | R2 |
| R5 | 3 | R3 |
| R6 | 3 | R3 |
| R7 | 4 | R4 |
Chaque routeur annonce périodiquement ses distances aux autres.
Le protocole RIP, bien que simple, présente plusieurs limites :
- il choisit les routes uniquement en fonction du nombre de sauts, sans prendre en compte la qualité des liaisons ;
- le nombre de sauts est limité à 15, ce qui empêche son utilisation dans de grands réseaux ;
- sa convergence est lente, ce qui peut provoquer des incohérences temporaires dans les tables de routage.
4.3. Gestion des pannes
Examinons maintenant le comportement du protocole RIP
lorsqu’une panne survient dans le réseau.
Supposons par exemple que le routeur R4 tombe en panne.
Dans ce cas, le routeur R7 ne dispose plus, à cet instant,
d’une route valide vers le réseau 3.2.1.0.
Le routeur R7 détecte relativement rapidement la disparition de R4. En pratique, cette détection repose principalement sur l’absence de réception des messages RIP périodiques envoyés par R4. Après un certain délai sans nouvelles informations, R7 considère que la route via R4 n’est plus valide.
R7 associe alors un coût infini (16 sauts dans RIP)
à la route vers le réseau 3.2.1.0,
ce qui revient à indiquer que ce réseau est injoignable.
Il attend ensuite de recevoir une meilleure proposition de route
de la part d’autres routeurs voisins.
Cette nouvelle route peut, par exemple, être annoncée par les routeurs R5 ou R6. R7 compare alors les différentes annonces reçues, choisit la route présentant le plus petit nombre de sauts et met à jour sa table de routage en conséquence.
Cette phase d’échange d’informations se poursuit jusqu’à ce que tous les routeurs du réseau possèdent à nouveau des tables de routage cohérentes : on dit alors que le réseau a convergé.
Ce mécanisme de gestion des pannes fonctionne, mais il peut être lent et provoquer des incohérences temporaires. Ces limites expliquent le recours à des protocoles plus performants, comme OSPF.
5. Routage par état de liens : OSPF
Le protocole OSPF (Open Shortest Path First) a été standardisé en 1990 afin de corriger les principales limites de RIP, notamment la taille des réseaux supportés et le temps de convergence. Il est aujourd’hui largement utilisé comme protocole de routage interne dans les réseaux de taille moyenne ou grande.
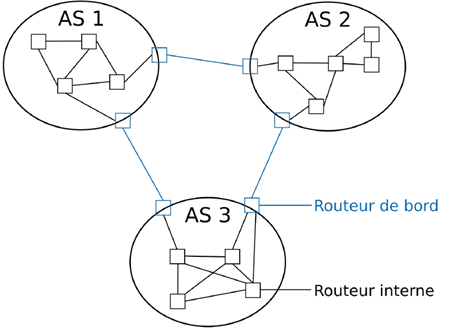
Un réseau utilisant OSPF est organisé en systèmes autonomes (AS),
c’est-à-dire des ensembles de routeurs gérés par une même organisation
et partageant un même protocole de routage interne.
Afin d’améliorer les performances et la scalabilité,
un AS peut être découpé en plusieurs zones OSPF,
structurées autour d’une zone centrale appelée zone 0
(ou backbone).
5.1. Principe général
Avec les protocoles à état de liens, chaque routeur cherche à obtenir une carte complète du réseau et calcule lui-même les plus courts chemins vers toutes les destinations, à l’aide de l’algorithme de Dijkstra.
Les grandes étapes sont :
- Découverte des voisins et de leurs adresses réseau (paquets
HELLO). - Mesure du coût de chaque lien vers ses voisins (paquets
ECHOou équivalents). - Construction de paquets contenant l’état de ses liens (LSA : Link State Advertisement).
- Diffusion de ces paquets à tous les routeurs de la zone (inondation).
- Calcul local des plus courts chemins sur le graphe obtenu (algorithme de Dijkstra).

5.2. Coût d’un lien
L’état d’un lien décrit les caractéristiques d’une interface (capacité, voisin, etc.). Dans OSPF, le coût d’un lien est souvent calculé à partir de son débit, par exemple :
coût = 10⁸ / débit (en bit/s)Plus le débit est élevé, plus le coût est faible, donc plus le lien est « attractif ». La distance administrative sert ensuite à départager différentes sources de routes (statique, OSPF, RIP…) lorsqu’un routeur apprend la même destination par plusieurs moyens.

5.3. Exemple d’utilisation de l’algorithme de Dijkstra
Considérons un routeur A qui souhaite trouver les meilleurs chemins vers tous les autres. Il découpe l’ensemble des routeurs en deux groupes :
- ceux pour lesquels il connaît déjà le meilleur chemin (groupe connu) ;
- tous les autres (groupe inconnu).

À chaque étape, A examine tous les liens reliant un routeur du groupe connu à un routeur du groupe inconnu, choisit le lien de meilleur coût, et bascule le routeur correspondant dans le groupe connu.

Idée clé : dans Dijkstra, le groupe des routeurs « connus » contient toujours ceux pour lesquels il n’existe pas de meilleur chemin possible (au pire un chemin équivalent).